
Копирайтер прислал не текст, а невнятное полотно с ключевыми словами? Подождите менять подрядчика, вначале проверьте, не было ли ваше техзадание похоже на это:

Если да, причина — в вас. Чтобы получить качественный текст, нужно составить подробное техническое задание. Такой контент пользователи ценят и охотно делятся в социальных сетях, мессенджерах, на форумах, а поисковые системы считают достаточно конкурентоспособным в борьбе за топовые позиции.
Технические требования к текстам
В задании должны быть описаны все требования к структуре, содержанию, объему, перелинковке, а также тезисы и ключевые запросы.
Какой длины должен быть текст
Забудьте об универсальных размерах текста, все индивидуально и зависит от:
- типа текста (коммерческий или информационный);
- тематики;
- типа страницы, для которой создается контент;
- размера текстовых блоков на сайтах конкурентов.
Для информационных статей большой объем — то, к чему стоит стремиться, а для коммерческих текстов важно раскрыть тему, при этом без воды.
Как определить оптимальную длину текста конкретно для своего ТЗ?
- Узнать объем аналогичного контента у конкурентов в топе.
- Проверить, раскрывают ли конкуренты тему полностью.
- Исходя из полученных результатов, определить необходимый объем для своей статьи или текста.
Также оптимальный объем по такому же принципу поможет определить модуль текстовой аналитики от Serpstat.
Что такое структура текста
Качественно структурированный скелет текста — обязательная составляющая технического задания.
Структура текста должна быть визуально разнообразной. Хороший пример — текст: «Как не пропустить рак: все, что нужно знать об онкологическом чек-апе».
Перечень обязательных требований к структуре и разметке текста, которые необходимо указать в ТЗ копирайтеру:
Заголовок h1

Заголовки h2-h6
Стандартное требование — не менее двух заголовков h2:
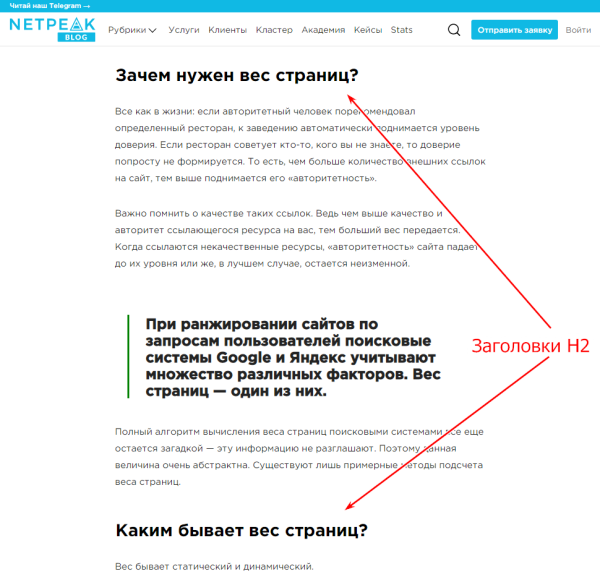
Нумерованный или маркированный список и таблицы

Блоки со сравнениями

Навигационное меню
Особенно актуально, если текст содержит большое количество заголовков:

[SEO настоящего] под микроскопомСтоит стремиться к структуре контента, описанной в посте «[SEO настоящего] под микроскопом». Ее можно дополнять и расширять подзаголовками, графиками, иллюстрациями.
Где найти иллюстрации
Картинки должны быть высокого качества. Рекомендую использовать бесплатные стоки изображений:
- https://www.pexels.com/;
- https://www.sitebuilderreport.com/stock-up;
- https://pixabay.com/;
- https://stocksnap.io/;
- https://unsplash.com/;
- http://jaymantri.com/;
- http://kaboompics.com/;
- http://www.designerspics.com/;
- http://isorepublic.com/;
- http://www.gratisography.com;
- https://negativespace.co/.
Также можно искать изображения в Google, на которых нет копирайта или вотермарков другого сайта, выбрав лицензию с разрешением использовать иллюстрации в рекламных целях:
- Заходим в расширенные настройки поиска по картинкам.
- Выбираем «с лицензией на использование в коммерческих целях».
Для всех изображений необходимо прописать атрибуты alt и title.
<img class=»aligncenter lazy» data-src=»[url изображения]» alt=»[Название изображения до 75-80 символов]» title=»[Поясняющий текст к изображению]»>
Например, <img class=»aligncenter lazy» data-src=»https://eхample.com/image-rose.jpg» alt=»Букет из роз» title=»На фото букет из 5 чайно-гибридных роз бордового цвета»>
Атрибут alt позволяет узнать, что изображено на картинке, когда пользователь не может ее увидеть. Например, если пользователь отключает загрузку картинок в браузере или возникают какие-то проблемы в ходе загрузки сайта. Кроме того, оптимизация названий картинок и атрибутов alt в теге <img> — плюс для поисковых систем при ранжировании сайта в поиске по изображениям, например, в Яндексе или Google Картинках. Текст из атрибута title выводится большинством браузеров при наведении курсора на изображение и дает дополнительную информацию про картинку.
Зачем нужна уникальность текста больше 90%
Немного о требованиях к уникальности контента — от Google и Яндекс.
Специалисты проверяют тексты с помощью сервисов:
- https://advego.com/plagiatus/ — с сайта Адвего можно бесплатно скачать программу и установить на свой компьютер (только Windows) и делать это гораздо быстрее, чем в онлайн-режиме;
- https://text.ru — можно сохранить ссылку на результат проверки;
- https://content-watch.ru/text/ — можно добавить сайт, который хотите не учитывать при проверке, например, если проверяете уже опубликованный текст.
Как построить внутреннюю перелинковку
Продуманная перелинковка страниц на сайте позволит равномерно распределить ссылочную массу. Количество входящих ссылок на страницу указывает поисковым системам на ее значение.
В техническом задании следует указать:
- количество: 1-2 ссылки на 1000 символов (для информационных статей допустимо больше);
- анкор (текст ссылки) соответствует странице, на которую ведет ссылка;
- добавлять ссылки стоит на целевые страницы (разделы, категории), а не только на смежные статьи;
- ссылки распределять равномерно по всему тексту.
- для всех ссылок прописать атрибут title. Единственный верный формат оформления ссылки в тексте: <a target=»_blank» href=»http://site.com» title=»тайтл»>анкор ссылки</a>, где в качестве атрибута title необходимо кратко и по существу описать, что расположено на странице, куда ведет ссылка.
Главное правило: добавлять ссылки в том случае, если они будут полезны пользователю.
Не рекомендую ставить ссылки на:
- служебные страницы (доставка, оплата, корзина) — нецелесообразно сливать на них внутренний ссылочный вес;
- на главную страницу сайта — это может дезориентировать пользователя;
- на страницу товара — он может быть снят с производства или быть не в наличии.
Категорически нельзя:
- прописывать ссылку со страницы на саму себя;
- ставить ссылки на одну и ту же страницу в пределах одного текста;
- ставить ссылки с одинаковыми анкорами в пределах одного текста;
- начинать текст, абзац или предложение со ссылки.
Зачем нужны исходящие ссылки
При использовании цитат или комментариев экспертов стоит ссылаться на авторитетные источники, это увеличит доверие пользователей. Особенно важно это для сайтов в тематиках «медицина», «финансы», «новости» (их объединяют в категорию YMYL — Your Money Your Life). Подробно о рекомендациях для таких сайтов — в обновленном руководстве для асессоров.Как вывести информационный сайт из-под YMYL фильтра Google — кейс maanimo.comЧитайте также, как вывести информационный сайт из-под YMYL фильтра Google.
Подготовка списка ключевых слов
Убедитесь, что собрали всю семантику для страниц сайта, иначе вы рискуете получить интересные статьи, которые не соответствуют запросам потенциальных клиентов и не раскрывают тематику страницы либо попросту не охватывают все необходимые поисковые запросы, в том числе «волшебные» LSI слова.
Но давайте разберемся со всем по-порядку.
Семантика: для чего она нужна
Семантическое ядро сайта, согласно википедии, — упорядоченный набор слов, их морфологических форм и словосочетаний, которые наиболее точно характеризуют вид деятельности, товары или услуги, предлагаемые сайтом. В семантическом ядре есть центральное ключевое слово, как правило, высокочастотное, а все остальные ключевые слова в нём ранжируются по мере убывания частоты совместного использования с центральным запросом.
Собирая семантику, SEO-специалист узнает, что именно и как ищут потребители (потенциальные клиенты). Так создают посадочные страницы под запросы пользователей, тем самым увеличивая вероятность посещения сайта и совершения на нем сделки, а также обеспечивая лучшее продвижение.
В магазине вы не ищите книги в витрине холодильника. Сайт — витрина, а семантическое ядро — как маркетинговое исследование, которое дает возможность понять взаимосвязь между товарами и их распределение на полках витрины.
Я для сбора ключевых запросов чаще всего использую Serpstat, Планировщик ключевых слов Google Ads и Яндекс.Вордстат.
Как собрать ключевые слова и найти упущенную семантику с помощью Serpstat
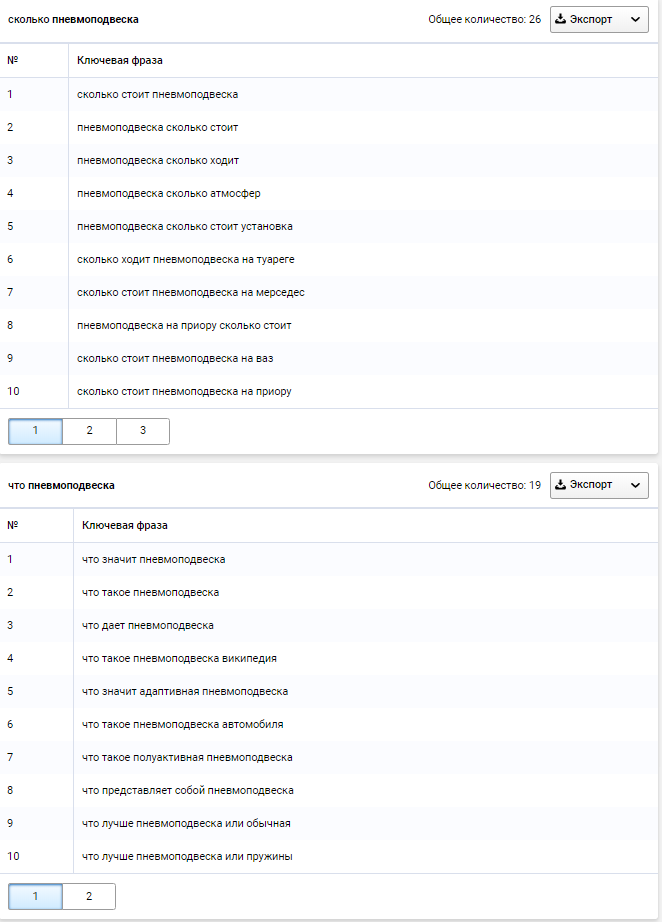
Подберем ключевые слова по запросу «пневмоподвеска» для региона Россия. Для этого в Serpstat добавляем ключевое слово «пневмоподвеска» и выбираем поисковую систему Google.ru. Также очень удобно использовать блок фильтров, с помощью которого я сразу исключила все фразы с неправильным написанием и частотностью менее 10:

В результате получаем кластер запросов (на скриншоте представлена его часть), в котором для написания ТЗ нужны колонки «Фраза» и «Частотность»:

Эти слова, а также запросы из раздела «Похожие фразы», необходимо выгрузить в удобный формат (таблицы Google, csv) и очистить от мусора. Для небольшого количества запросов я использую фильтры в Google таблицах, а для больших объемов — Key Collector. Можно использовать его бесплатный аналог — Словоёб.
Набор минус-слов зависит от ресурса, для которого подбирается семантика. Для интернет-магазина необходимо удалить:
- все дубли;
- фразы со словами:
- своими руками;
- посоветуйте;
- дешево, недорого;
- б/у (и все его вариации);
- каталог (это информационный запрос);
- обмен, ремонт, установка, установить, замена (и прочие услуги, которые не предоставляет ваш магазин);
- плюсы и минусы;
- рейтинг;
- что лучше;
- все о…;
- сколько стоит, стоимость;

- названия конкурентов;
- названия ТМ, с которыми вы не работаете;
- названия марок автомобилей, для которых у вас нет товара (подсказка: если планируете расширять ассортимент, то вынесите такие запросы в отдельный кластер и проанализируйте спрос);
- названия других запчастей выделяете в отдельный кластер;
- топонимы, которые не соответствуют вашему региону доставки.
В результате получаем качественные ключевые слова:

Для анализа упущенной семантики хорошо подойдет инструмент «Текстовая аналитика» от Serpstat.
Создаем проект. Если готовим ТЗ для текущего сайта, то задаем адрес домена:

Добавляем собранные ранее ключевые фразы:

Указываем поисковую систему и страну поиска:

Указываем силу связи и тип кластеризации. Если сайт многокатегорийный, то выбираем weak-soft (больше кластеров), а если сайт по продаже, например, кроссовок, то выбираем medium/strong-hard:

Запускаем процесс кластеризации. После окончания система автоматически подбирает соответствующий url под кластер. Если вы не согласны, то можете заменить его вручную.
Запускаем текстовую аналитику и получаем полную информацию:

«Коэффициент штиля» показывает, насколько тематика данной фразы похожа на тематику других фраз из этой группы, а «Релевантность» показывает, какая ключевая фраза соответствует целевой странице в сравнении с конкурентами.

В разделе «Текстовая аналитика» отображаются упущенные ключевые слова для h1, title и body, а также не вошедшие в рекомендательную базу, но присутствующие на страницах конкурентов ключевые запросы. Они находятся внизу списка рекомендуемых и отсортированы по значимости:
В блоке «Body текст» анализируется текст на целевой странице сайта между тегами <body> и </body>. Алгоритм Serpstat изучает количество слов в тексте, сопоставляет его с конкурентами в топе и дает рекомендации по уменьшению или увеличению его объёма, а также показывает ошибки на заданной странице:

Делаем вывод: рекомендуемый объем текста около 1500 слов.
Как найти ключевые слова с помощью Планировщика ключевых слов Google Ads
Если в аккаунте есть активные кампании, частотность запросов будет показываться точная, если кампаний активных нет — будет показываться диапазон частот.
Выбираем «Инструменты и настройки» — «Планировщик ключевых слов»:

Затем жмем «Найдите новые ключевые слова», вводим ключевое слово и задаем регион поиска. Также в Google Ads, как и в Serpstat, можно посмотреть, по каким ключам ранжируется страница вашего сайта.Главные секреты планировщика ключевых слов GoogleЧитайте также о главных секретах Планировщика ключевых слов Google Ads.
Как найти нужные LSI слова
Необходимо учитывать не только стандартные поисковые запросы, но и околотематические:
- синонимы («пневмоподвеска» — «пневматическая подвеска», «покрышки» — «шины»);
- транслитерации (например, бренд пневмоподвесок: Firestone и Фаерстоун, бренд покрышек: Michelin и Мишлен);
- сленг («пневма», «колеса», «резина»);
- общетематические слова (авто, запчасти, машина, автомобиль).
Google Колибри — все, что вы хотели знать о новом алгоритмеGoogle стремится понимать пользовательские запросы, именно поэтому важно учитывать ключевые слова Latent Semantic Indexing (LSI) — семантически родственные. Система LSI еще шесть лет назад стала основой апдейта Колибри, и с тех пор роботы Google просматривают страницы и ищут слова и фразы, максимально близкие или родственные по значению к вашему ключевому слову.
Если вы составляете ТЗ к статьям блога для мам, то LSI фразами для запроса «новый год» будут «подарки на новый год», «идеи подарков на новый год», «подарки на новый год детям», «что подарить ребенку трех лет».
LSI фразами для по запросу «пневмоподвеска» будут «почему пневмоподвеска умирает так быстро», «что такое полуактивная пневмоподвеска», «ручной и автоматический режимы работы пневматической подвески».
Система LSI сопоставляет базу ключевых слов с запросами пользователя. Благодаря этому, подбор LSI слов позволяет:
- улучшить поведенческие факторы за счет качественного и интересного контента;
- улучшить ранжирование статьи по НЧ запросам;
- снизить спамность текста за счет использования синонимов;
- обеспечить естественное наращивание ссылочной за счет вирусного контента.
Качественный контент и релевантность выдачи — именно то, за что борется Google, поэтому LSI слова в контенте страницы помогут улучшить ее рейтинг.
Для подбора LSI слов используют различные методы:
- подсказки поисковой выдачи:

- «Похожие фразы» и «Поисковые подсказки» в Serpstat (платный сервис, есть тестовый период):

- блок «Вместе с… часто ищут» внизу поисковой выдачи на первой странице Google:

- правая колонка Яндекс.Вордстат:

- инструмент «Вместе с запросом ищут…» от сервиса Пиксель Тулс. Требуется только регистрация, для частного использования вполне хватает 250 лимитов в тарифе «стажер»:

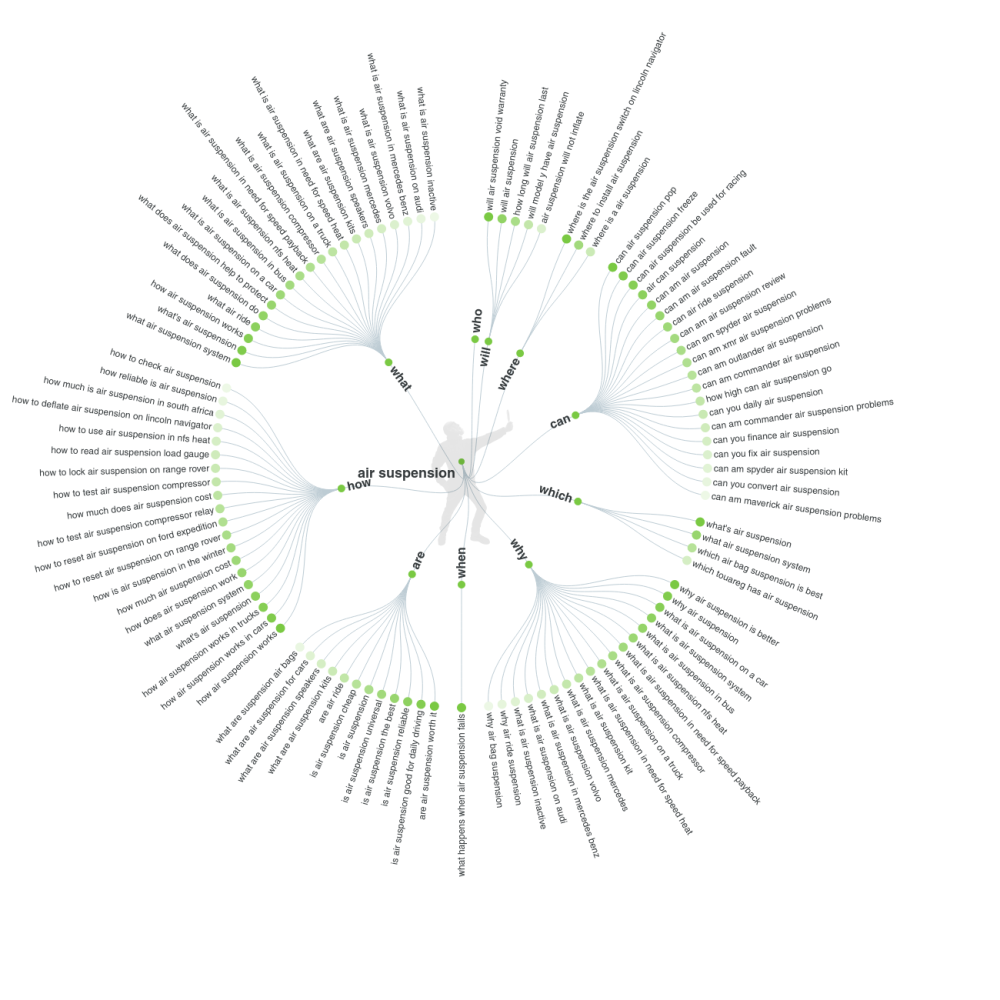
- сервис http://lsigraph.com/ — бесплатный с ограниченными функциями до трех запросов на английском и для региона США. Для расширения региона анализа, изменения языка и увеличения числа лимитов необходима платная подписка. Кроме LSI слов, сервис также показывает топ страниц по запросу. Результат поиска для запроса «air suspension»:

В конечном итоге слова LSI помогают пользователям получить доступ к более качественному контенту и улучшить рейтинг страниц.
Как сформировать список ключевых слов
При перечислении ключевых слов важно указывать высокочастотные (ВЧ), среднечастотные (СЧ) и низкочастотные (НЧ) запросы, а также добавлять транзакционные и гео- запросы для интернет магазинов. Также важно указывать уникальное торговое предложение вашего сайта (например, гарантия — два года).
Стоп-слова (вводные) для текстов
Важно не перегружать текст стоп-словами (или шумовыми словами) — это лексические единицы, лишенные смысловой нагрузки. К стоп-словам относят чаще всего союзы, предлоги, вводные слова.
Например:
- вводные конструкции (как известно, не секрет, кстати);
- оценка чего-либо без подтверждения фактами (в отдельных случаях «полезный продукт» лучше заменить на «цельнозерновой хлеб с сухофруктами и орехами»);
- штампы (команда профессионалов, экспертная оценка);
- заумные слова;
- эвфемизмы (некорректные синонимы, которые чаще всего применяются при критике и/или оценивании чужой работы);
- отглагольные слова (не «занимаемся продажами», а «продаем»);
- завуалированная ложь (кто, как не мы, лучше всех разбирается в кулинарии).
Оптимальная концентрация стоп-слов по отношению к общему количеству слов в тексте составляет около 30%.
Написание тезисного плана для текста, или Где взять идеи
Чтобы копирайтер понимал основную задумку и раскрыл важные для читателя темы, необходимо составить тезисный план статьи.
Составляем тезисы с помощью Arsenkin.ru
Инструмент https://arsenkin.ru/tools/check-h/ парсит выдачу заголовков h1-h6 по заданной ключевой фразе в Яндекс до топ-15. Для парсинга Google нужна платная подписка.
Результат для фразы «подарки на новый год»:

Для запроса «пневмоподвеска»:

Мы сразу видим, по каким тезисам (заголовки h2-h6) страницы-конкуренты попали в топ-15, и можем учесть их в своем ТЗ. В результате сможем в статье максимально полноценно раскрыть интересующую тему, собрав на одной странице самые важные для читателя моменты.
Пишем тезисы с помощью Serpstat
Идеи можно найти в блоке «поисковые вопросы» в разделе «контент-маркетинг»:
Также можно проанализировать тексты конкурентов с помощью функции «Анализ доменов». Там же можно найти упущенные ключевые слова, по которым ранжируются ваши конкуренты, но не ранжируется ваш сайт, и добавить их в ТЗ.
Пишем тезисы с помощью Ahrefs
Заходим в раздел «Keywords Explorer» и блок «Keyword ideas»:

Используем Soovle, Answerthepublic
Бесплатный аналог Ahrefs — https://soovle.com/, больше подходит для западных проектов. Особенно интересна колонка Answers.com, в которую стоит заглянуть, если закончились идеи:

Еще один бесплатный аналог Ahrefs для западных проектов — https://answerthepublic.com/:
Пишем тезисы с помощью BuzzSumo
BuzzSumo.com показывает контент, который больше всего шерили. Есть бесплатный тестовый период 7 дней:
- вставляем ссылку на сайт или ключевое слово;
- сортируем шеринг по определенной соцсети или по общему количеству;
- ищем идеи в списке самых популярных статей.

Как и в прошлом случае, здесь можно собрать больше идей для англоязычного контента.
Собираем тезисы из программ курсов и обучающих семинаров
Алгоритм простой:
- ищем платформы с курсами;
- смотрим описания курсов — там кладезь тем;
- для каждого курса есть программа — вот и готовая структура тезисов для статьи. Например, https://www.udemy.com/:

Запомнить
- Забудьте об универсальных размерах текста, все индивидуально и зависит от типа текста, тематики, типа страницы, размера текста у конкурентов.
- Качественно структурированный скелет текста — обязательная составляющая технического задания.
- Картинки лучше всего брать из бесплатных фотостоков или в поиске «с лицензией на использование в коммерческих целях».
- Количество входящих внутренних ссылок на страницу указывает поисковым системам на ее значение для сайта в целом.
- При использовании цитат или комментариев экспертов стоит ссылаться на авторитетные источники, это увеличит доверие пользователей.
- Вне зависимости от метода сбора ключевых слов, вам не избежать этапа их очистки от мусора. Нет универсального набора минус-слов — всё зависит от ресурса, для которого подбирается семантика.
- Необходимо учитывать не только стандартные поисковые запросы, но и околотематические.
- Оптимальная концентрация стоп-слов по отношению к общему количеству слов в тексте составляет около 30%.
- Идеи для тезисов статьи можно найти с помощью парсинга выдачи конкурентов, просмотра поисковых подсказок, аналитики популярных статей по теме или программ курсов и обучающих семинаров.
Хотите качественный текст — составляйте детальное техническое задание.